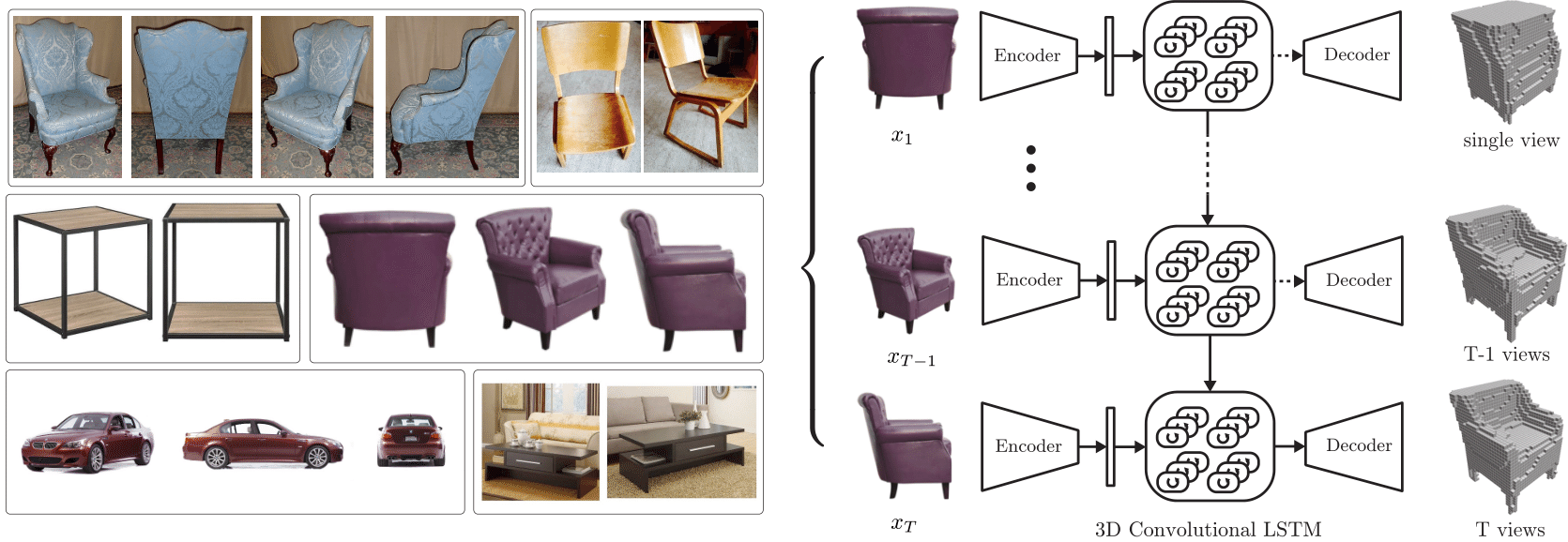
Multi View 3D Models From Single Images With A Convolutional Network. ⨁ represents the concatenation of image features and vertex coordinates. Figure 9 shows the architecture proposed in the paper, which is almost exactly what we explained above.
Given one or multiple views of an object, the network generates voxelized ( a voxel is the 3d equivalent of a pixel) reconstruction. 90% styles, all viewpoints available • “target set” : The cnn is used for extracting image features from a single projection image, and the gcn is for learning 3d deformation.
[18] Predicted Deformations From Mean Shapes Trained From Multiple Learning Signals.
The input to the network is a single image and the desired new viewpoint; We present a convolutional network capable of inferring a 3d representation of a previously unseen object given a single image of this object. We present a convolutional network capable of inferring a 3d representation of a previously unseen object given a single image of this object.
Concretely, The Network Can Predict An Rgb Image And A Depth Map Of The Object As Seen From An Arbitrary View.
Figure 9 shows the architecture proposed in the paper, which is almost exactly what we explained above. Several of these depth maps fused together give a full point cloud of the object. One reason for this result is the relative efficiency of the
The Same Architecture Can Be Applied To Accurately Recognize.
Givena3dmodel(orasetof3dmodels)andanimagewelocateandalignthe model in the image. We present a convolutional network capable of inferring a 3d representation of a previously unseen object given a single image of this object. Pedestrian age and gender identification from far view images using convolutional neural network.
Recognition Rates Further Increase When Multiple Views Of
The first module is sketch component segmentation based on multimodal dnn fusion and is used to segment a given sketch into a series of basic units and build a transformation. Because these techniques use natural images without additional information as. Eunbyung park, jimei yang, ersin yumer, duygu ceylan, and alexander c.
Concretely, The Network Can Predict An Rgb Image And A Depth Map Of The Object As Seen From An Arbitrary View.
Recognition rates further increase when multiple views of the shapes are provided. Interpolate missing angles in the target set 15 azimuth angles available The mvcnn is trained to process each 3dfis and generate a denoised image stack t.




0 Comments